
Сравнение трех нейросетей VisGPT для перевода аудио в текстовый формат на примере диалога с распознаванием спикеров по ролям
В агрегаторе нейросетей VisGPT есть целых три нейросети, которые могут перевести любую аудиозапись в текст
Варианты их использования:
Мы решили сравнить, кто лучше справится с распознаванием диалога. Это телефонный разговор, который содержит технические слова, посмотрим какая нейросеть более точно их распознает.
В сервисе VisGPT выставляем фильтр нейросетей для работы с аудио.
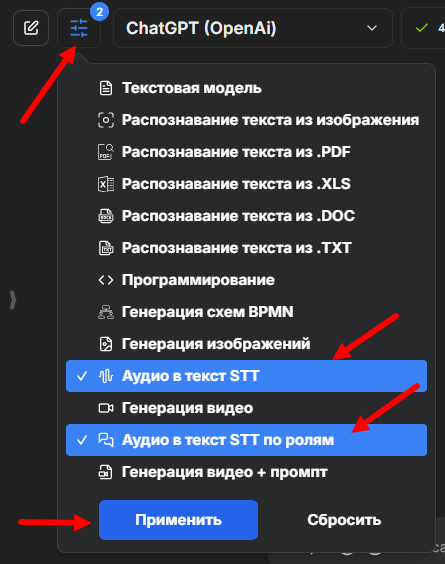
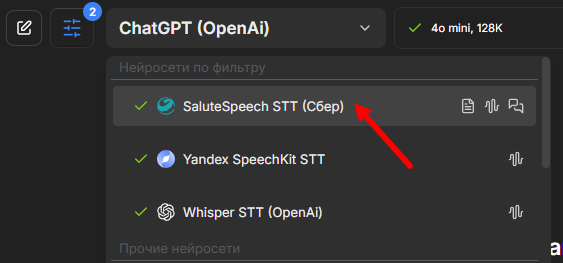
Первым будет SaluteSpeech от Сбера:
Загружаем аудиозапись и пишем запрос:

Вот что получилось:

Текст удобно читается, речь каждого спикера начинается с новой строки. Есть проблемы с корректным написанием названий нашего сервиса и некоторых нейросетей. Ставим 7 из 10.
В этом же окне меняем нейросеть на Yandex SpeechKit:
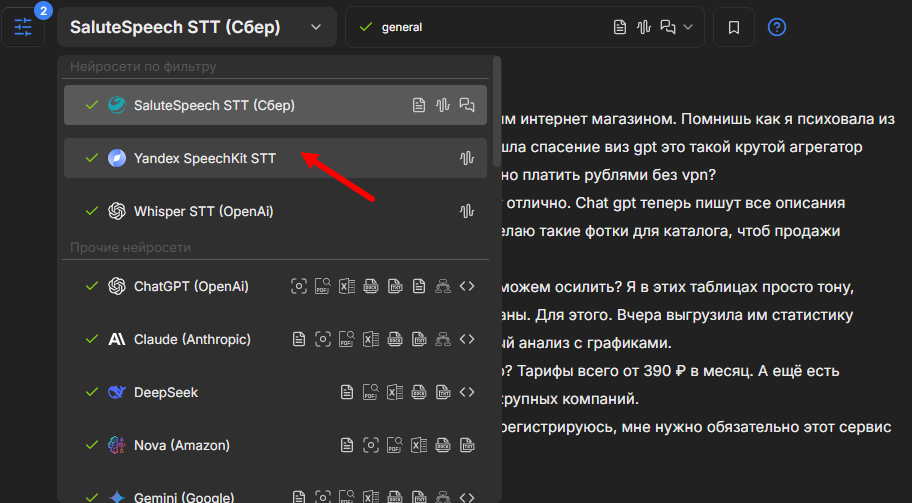
Повторяем действия - загружаем аудио и пишем запрос. Вот результат:
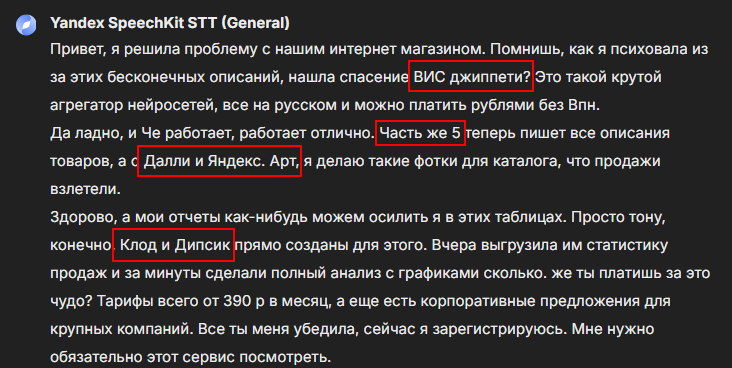
Смена говорящего не так заметна, предложения идут подряд. С названиями та же беда, VisGPT совсем искаверкал. Хотя Далли и Дипсик звучат более точно, чем у предыдущего испытуемого. Ставим 6 из 10.
Третьей будет нейросеть для распознавания речи Whisper от OpenAi:
Повторяем процедуру и оцениваем результат:
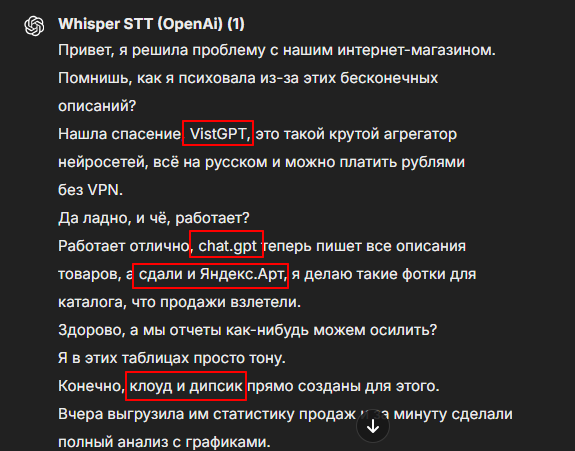
Диалог узнается слабо, похоже на сплошной текст. С названием VisGPT оказался ближе всех, но остальные также хромают. 4 из 10.
Теперь, чтобы превратить это в удобно читаемый диалог, возьмем самый удачный вариант от Salute и перейдем в нейросеть Claude. Мы как раз добавили новую продвинутую версию 3.7.
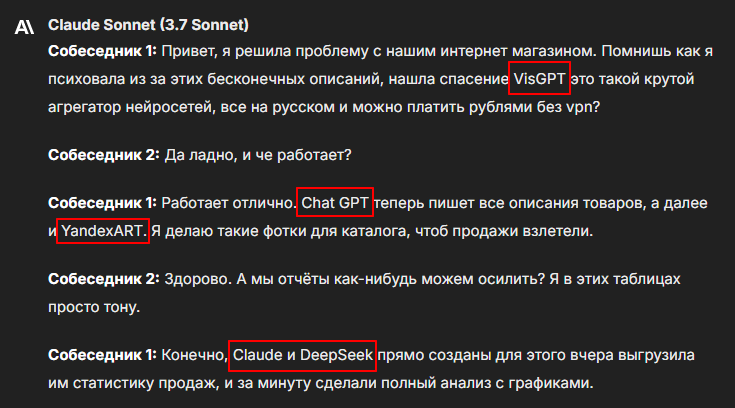
И просим разбить по ролям и поменять на корректные названия:

Получаем разговор, разделенный на двух спикеров с правильными названиями:
Поможем подобрать индивидуальное предложение под ваши задачи:
📩 ai@vis.center
📞 +7 495 177-37-13
Перейти к облаку тегов
Перейти к блогу